Data of Feelings
Download
A kód automatikusan kiválaszt érzéseket, amikhez véletlenszerűen generál értékeket. Majd ezeket az érzéseket
munkahelyi aktivitásokhoz köti. Az értékek 'First moment', 'Second moment', 'Third moment' csoportban vannak.
Magyarán egy érzéshez 3 pillanatnyi érték tartozik, amit egy munkahelyi aktivitáshoz párosít.
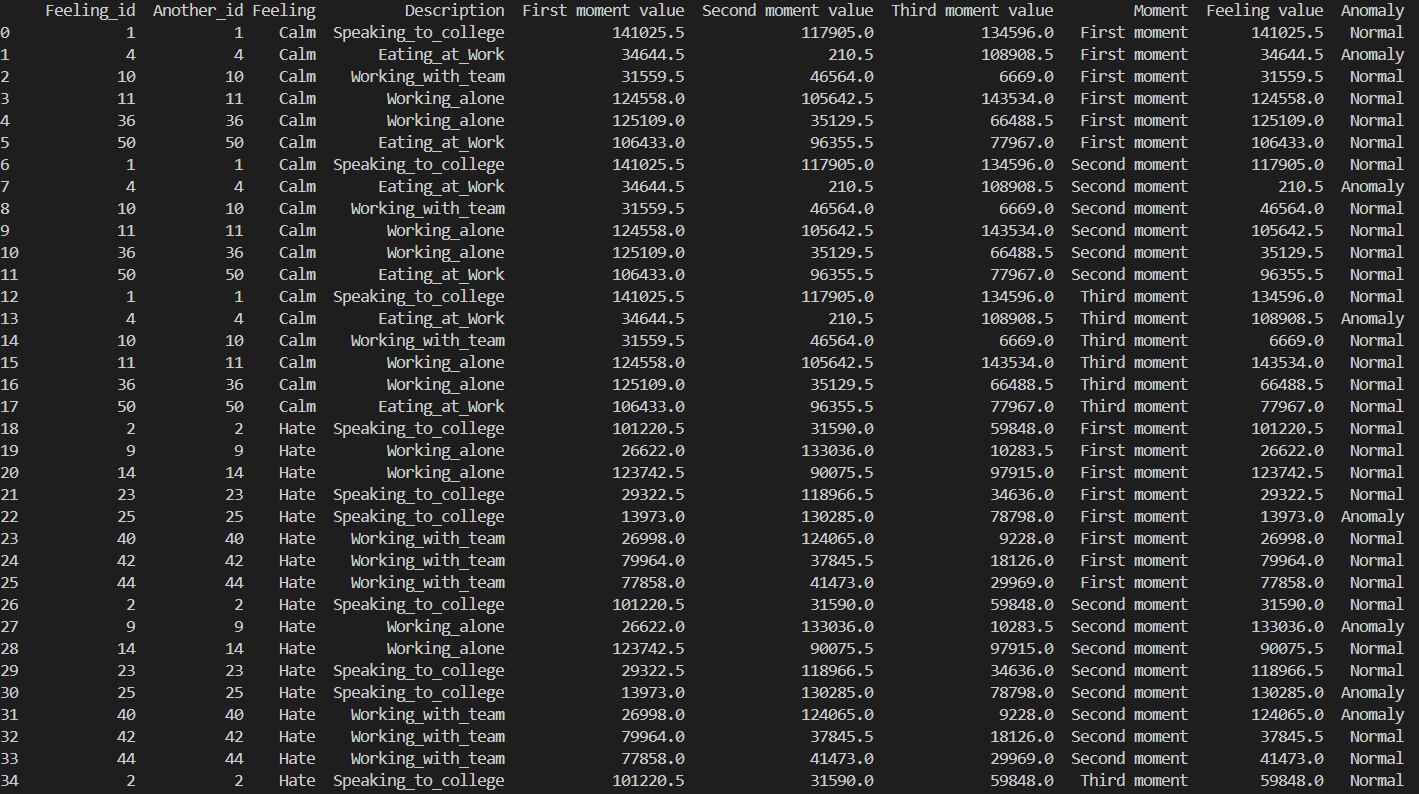
Ezek az adatok adatbázisban tárolódnak. A kód index alapján egy másik táblában eltárolja a pillanatokat
és értékeit szétválasztva.
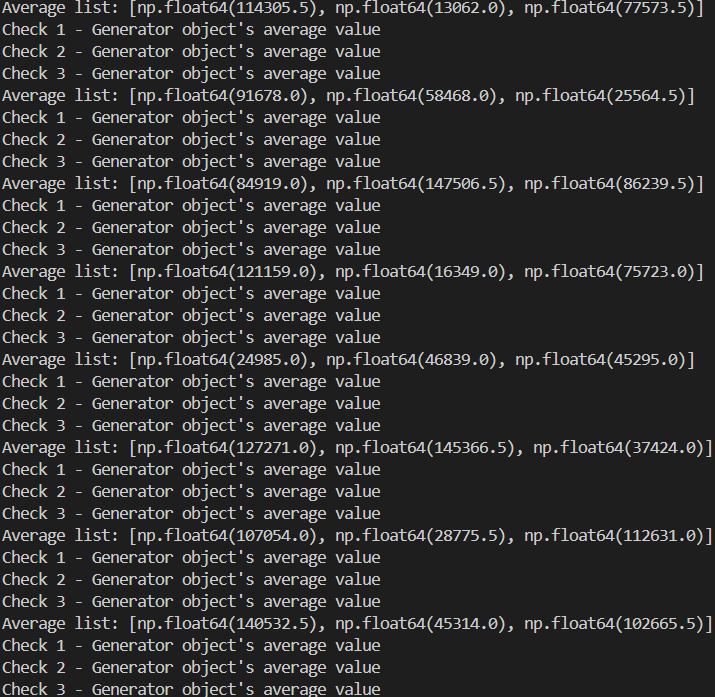
Érzések és hozzájuk tartoz értékek generálása.
DataFrame-ben az elkészült véletlen adatok.
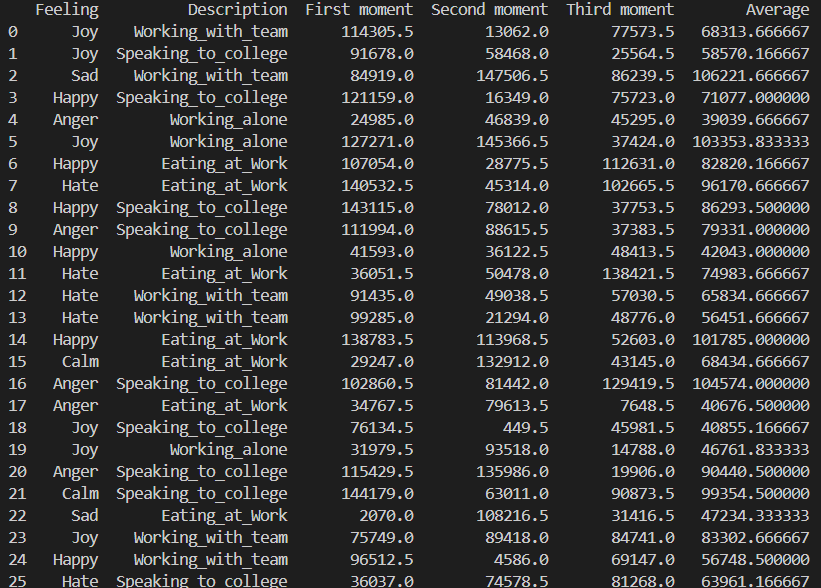
Másik adatbázisban a szétválasztott pillanatok.
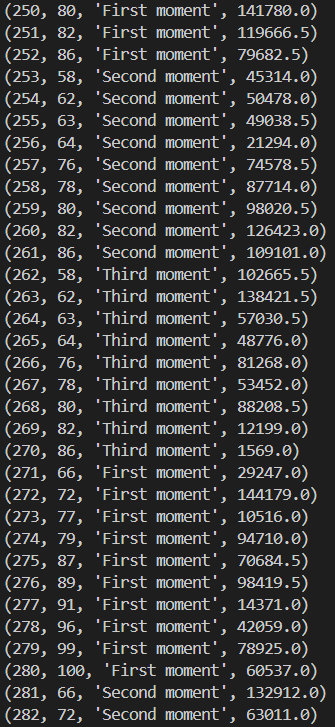
Inner query lekérdezés a további elemzéshez.
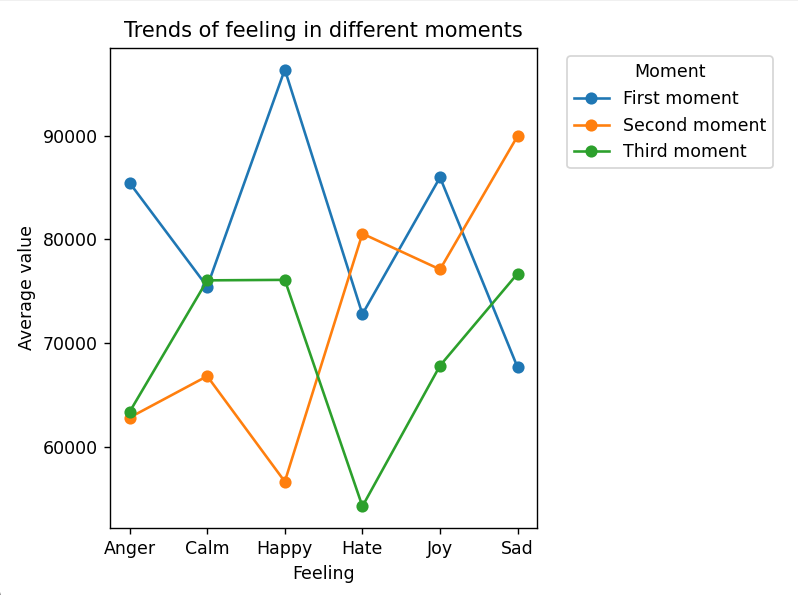
Adatok vizualizálva Matplotlib könyvtárral.
Csoportosítjuk a tevékenységeket és érzelmi állapotokat klaszterezési algoritmussal, példában K-means alkalmazással.
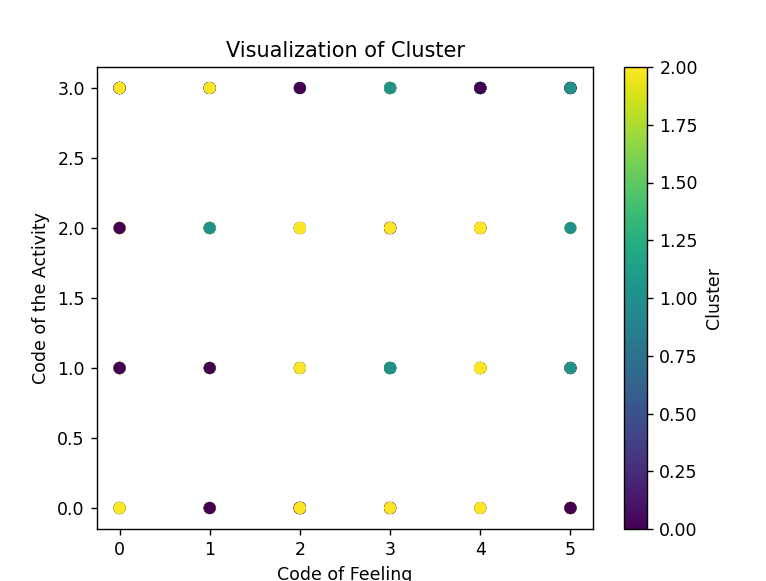
Az érzelmeket (pl. "Joy", "Sad") numerikus értékekkel helyettesíthetjük. Például a "Joy" 0-ként, a "Sad" 1-ként.
A tevékenységeket hasonló módon kódolhatjuk. Például az "At_Work" tevékenység 0, az "At_home" 1, stb.
Ez a klaszterezés segít jobban megérteni, hogy hogyan alakulnak ki az érzelmi állapotok különböző tevékenységek és
környezetek között. Az eredmények azt mutatják, hogy a "Hate" érzelem például különböző tevékenységekkel, mint a
munkahelyi helyzetek vagy a tévénézés, különböző klaszterekhez tartozik, ugyanakkor a "Sad" érzelem
és a "Speak_to_girlfriend" tevékenység egy másik klasztert alkotnak.
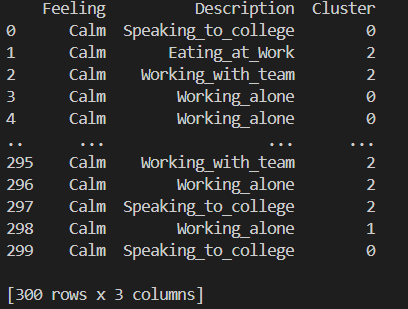
A 'Cluster' oszlop tartalmazza, hogy melyik adat tartozik melyik klaszterhez. Az egyes klaszterek vizsgálatával
megérthetjük, hogy mely érzelmi állapotok és tevékenységek vannak hasonló mintázatokban.
Az anomália detektálás segíthet azonosítani azokat az eseteket, amikor valami szokatlan történik, például egy
érzelem hirtelen változása egy adott tevékenység során.
Ezek az algoritmusok segíthetnek azonosítani azokat a viselkedéseket, amelyek nem illeszkednek a szokásos mintákhoz.
Egy adott tevékenység vagy érzelmi állapot elterjedtől eltérően viselkedik, és jelezheti, hogy valami fontos változás
történt.
Az Isolation Forest egy hatékony algoritmus, amely az adatok "izolálásával" találja meg az anomáliákat. Az algoritmus úgy működik, hogy véletlenszerűen választ egy adatpontot, majd azt különböző módokon "elválasztja" a többi adatponttól. Azok az adatpontok, amelyeket könnyen el lehet választani a többiektől, nagyobb eséllyel tekinthetők anomáliának.
A kód több szálon fut. Valamint tartalmaz adatbázis visszaállítást (Restore).
Adatkezeléshez és elemzéshez (Pandas, SciKit-Learn, SQLite3, MultiThread, Matplotlib) kiváló gyakorlás.